
Hi all, I’m Spencer, the “kid” who made this. I’ll do my best to explain, I promise it’s not as intimidating as it looks. If you have any questions after reading this, feel free to ask us on Twitter at @CAH.
OpenAI’s “GPT-2”
The Cards Against Humanity AI is built on top of a neural network called “GPT-2” made by OpenAI. GPT-2 is designed to generate realistic-looking text. To understand it, I'd really recommend watching the computerphile videos, but I'll do my best to explain it here.
Neural networks are algorithms capable of learning when given lots of data. Think of the YouTube recommendation system. It learns what videos you like based on all the data you give it: what you watch, what you thumbs-up, etc. Generally, neural networks are given some sort of input, and then asked to make a prediction, which is called the “output.”
GPT-2 uses text as its input and tries to predict the word (or punctuation) that comes next in that text. So, if given “Bananas”, it tries to predict the next word, and it might come up with “are.” Then you feed it both words — “Bananas are” — and it does the same thing. It might predict that “in” comes next. Now just keep doing that over, and over and eventually you’ll have entire paragraphs.
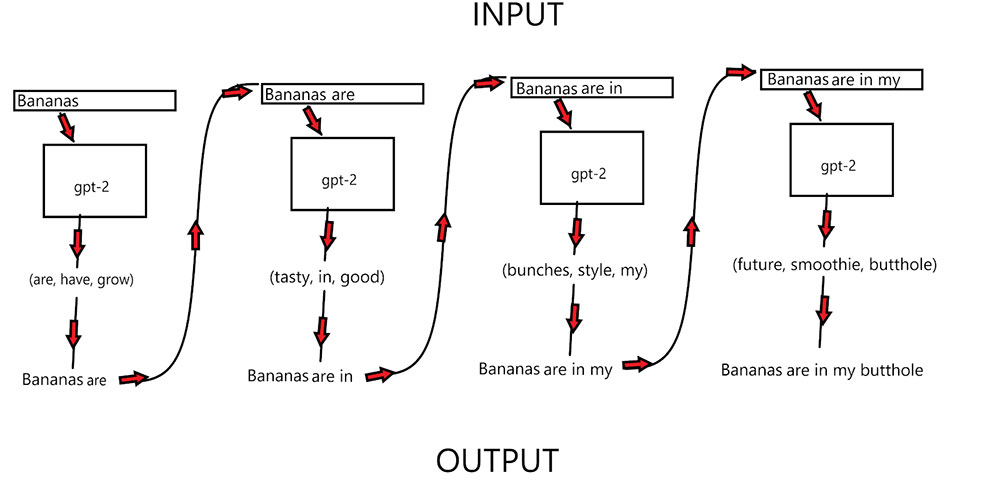
When it predicts the next word, it actually predicts a whole bunch of words that seem like they could be next and randomly selects one of them. Technically, it assigns a probability distribution across all possible words and then uses that distribution to select the next word.
This randomness is part of what makes it creative and lets it generate something new every time you run it. Since it was trained on so much data, there’s rarely one right answer to “which word should come next?”
›››››› TL;DR: GPT-2 generates new text by imitating text it’s seen before, with some added randomness.
Training the Neural Network to Write Cards
GPT-2 works well for many different language generation tasks because of a process called “transfer learning.” This is where a network trained on a general task is then fine-tuned to a more specific task. The knowledge of the general task helps the network learn the specific task faster and better. Think of teaching someone chemistry. Might it be easier to teach them if they already know how to do high-level math?
In our case, OpenAI already trained the network on 40 GB of Internet text. To put that in perspective, a 400 page book is generally about 1 MB. So, 40 GB of text is roughly equivalent to 40,000 books. What that means for us is the network already knows how to generate realistic-looking text and it also has a lot of cultural information encoded in it. So, all we need to do is train it on what white cards look like and what types of content they contain.
Drawing by my girlfriend @akpaley
This was done by taking that pre-trained network and then training it further on the text of 44,000 white cards. That includes all (roughly) 2,000 cards in the official game, another 25,000 internal brainstorming cards that never made it into the game, and 17,000 unofficial cards from fan-curated lists.
We stopped the training once it could “consistently” produce cards matching the grammar and tone of the game. We did this so it didn’t draw too much from already-written cards while still leveraging as much cultural information as possible.
›››››› TL;DR: GPT-2 was already smart enough to make realistic-looking text. We just fed it a bunch of cards until it learned what we wanted from it.
Generating and Filtering Cards
As I said before, GPT-2 lets us control the weirdness and creativity of its output. Each time it adds a word, it assigns a probability to all possible next words based on what it has learned. If we narrow the choices for the next word down to just the few most-likely words, the network will be less creative. Cards all start sounding the same and generally just suck. On the other hand, if we make the network too creative, it stops making sense and starts to sound like it’s just randomly pulling words from the dictionary.
Another fun thing we can control is how a card starts. Normally, we let the network pick the first word of the card, but we can also prompt it with phrases we know work well. For example, we could give it the prompt “Some kind of”, and it could complete that card as “Some kind of sci-fi oatmeal” or “Some kind of otter-themed sexy sea otter print pantsuit.” Most of the cards we generate are random (no prompt), but a decent fraction were made with a list of prompts we found worked well after some testing.
As a side note, card generation actually happens a lot faster than the printer is showing. On my personal computer, 20 cards can be generated per second, even after filtering out bad cards. It didn’t take that long to train the network, either. While it would take months for a single computer to train the original network, fine-tuning it to generate cards took less than an hour.
As we’re generating cards, we want to be able to automatically eliminate as many “bad” ones as possible. We can’t use an algorithm to eliminate unfunny cards (at least, not yet), but there are several other ways we can filter out bad cards.
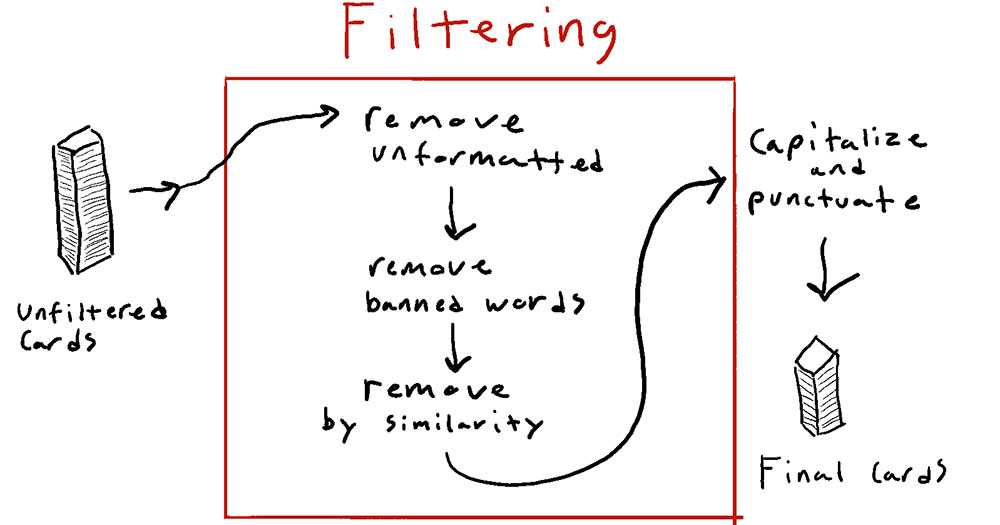
The first filtering step is a simple check to make sure the text is formatted the way we expect cards to be formatted. If it’s not, we’ll discard it and move on. The network is pretty great at following the formatting we trained it to follow, so only a few percent of cards are thrown away for this reason.
Next, we filter out cards containing any words on our banned-words list. This includes words we’d simply never print, along with jokes we don’t trust the algorithm to tell with any kind of cultural awareness. This step also removes only a few cards.
Our main filtering step is to remove cards that are basically copies of cards that already exist (either in a published set, or in an internal list somewhere). GPT-2 is trained to reproduce text it’s seen, so generating copies is inevitable. Sometimes this means letter-for-letter copies of existing cards, but more often it will change, add, or remove a few words or spell them differently. "A falcon with a cap on its head" is basically the same idea as "A falcon with a funny hat.” So we use fuzzy string matching to see how similar a new card is to every one of the 44,000 cards we trained the network on. This step throws out just about 50% of the generated cards and takes almost as long as the initial generation did, functionally quadrupling the time it takes to generate cards.
As a side note here, we also found that cards below a certain similarity threshold were basically garbled text, so we filter those out as well. This removes cards like “ಠ益ಠ”, “~~~~~~~~~~~~~ meh”, and “2+2=5.” Turns out any card that makes sense is going to be at least somewhat similar to one of the 44,000 cards we used to train the network.
Finally, we capitalize the cards and add periods if the model didn’t already do that. No filtering here, we just like things looking pretty.
›››››› TL;DR: We have control over some aspects of how the cards turn out. And we can automatically filter out cards that sound too much like cards that already exist.